
Risk Severity Levels Do More Harm Than Good
The information lost in modeling risk in qualitative severity levels is not made up for with the value it provides.

Rick severity levels such as “Critical” and “High” are ubiquitous in our field. However, I’ve yet to see many people question the usefulness of such a qualitative risk model. Every program seems to blindly use this model to classify and communicate risk without any thought on the costs of using such a model.
The Core of the Problem
Ultimately, this falls into a classic problem we deal with in cybersecurity: Fitting a model on top of another model.
First, a security engineer will create a model of reality based on their findings. This model will contain some amount of error depending on the biases of the engineer and the fidelity of the available information.
We can think of this risk formula being called f(x).
In the case of vulnerability severity, we can call the function that translates a risk calculation into a vulnerability severity, g(x).
Now, we must translate risk into some vulnerability severity which is what causes the issue.
This function would be g(f(x)). The g(f(x)) problem is one of the most pernicious and unnoticed problems I’ve encountered in cybersecurity.
The reason is that the error in f(x) is usually unknown since it is a model on top of reality, represented by x. If f(x) has significant error then we have a severely distorted view of reality and the effect on the final value g(x) is tremendous.
Bureaucratic Drivers
One of the biggest drivers I’ve seen for vulnerability classifications is that they are defined in compliance frameworks. I believe it is useful for these compliance frameworks to be generic since they need to apply to vast assortment of environments and need flexibility in order to work. Thus, I don’t believe that this fundamentally needs to change in regard to compliance.
However, this has led to an institutional norm of using risk severity levels across all cybersecurity decision making since it is what risk management folks are used to when dealing with. This was done with little to no thinking about whether or not this was the right model for security rather than compliance.
Lost Information, No Gain
There is very little consensus on what a “High” or “Critical” severity means across an organization since compliance standards do not enumerate any meaningful mapping and this scale is largely formed out of norms on a team-by-team basis. For example, your blue team and red team probably don’t have the same mental model of what issues fall into “Critical” vs “High”.
Let’s take a moment of silence for all the folks hassled into urgently prioritizing “Out-of-Support OS” critical “vulnerabilities” over actually exploitable issues.
We must take a step back and think about the Low, Medium, High, and Critical severity levels we typically see. These are 4 discrete values interchangeable with the integers 1 through 4. Thus, we have a situation where particular risk only has 4 possible messages and subsequently can only communicate 1 of 4 possible pieces of information.
Further complicating this, our risk severity function completely obfuscates f(x). This leads to unnecessary back-and-forth between security/compliance and the engineering teams as they often need the actual value of f(x) to understand the impact and prioritize the work.
Now, we are left with a situation where we have reduced the amount of information that can be communicated down to 4 possible messages and removed any ability to derive the function that led to those states.
This is why many of you have either experienced or committed the cardinal sin of labeling a risk based on vibes and not any repeatable or measurable process.
Vibes-based-Security
I am a firm believer that these qualitative risk classifications have reinforced “vibes-based-security” or security decision making based on whatever level the person making the decisions feels the risk is.
Don’t get me wrong, there are some great security vibe leaders (can we make this a thing?) out there who make great decisions because their mental model is more accurate than any formulaic model. However, most of us, are just not that good and even those people are human and will have lapses in judgement.
This has led us to be quick and lazy in our decision making because we feel that we can just determine what severity a risk is by looking at the available information. Ultimately, this leads to a ton of variability and errors in our risk classification process.
The example below illustrates this fact:
Dataset 1 in blue represents 5 employees where their baseline was chosen randomly from a normal distribution with mean 1. Then 50 points were taken from 5 normal distributions with the employee baseline as the mean and a variance between .01 and .3 for up to a 30% deviation from their baseline.
Dataset 2 in red represents those same 5 employees operating on a formulaic model that has a mean of 1 and a variance between .01 and .3 for up to a 30% deviation from their baseline.
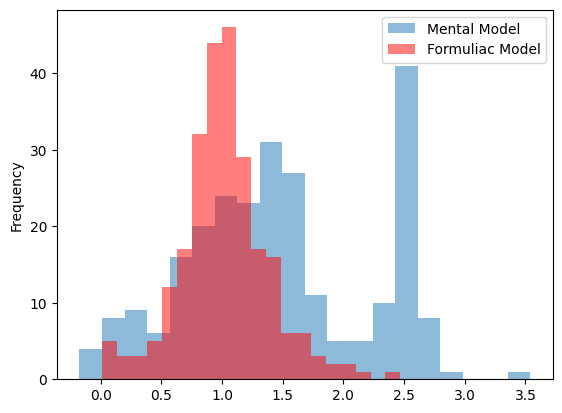
This shows that the variance for the individual models are far higher and thus represent much more risk of a miscalculation. The formulaic model, operating as a center of gravity, provides much more precision across observations.
This has considerable implications for improving accuracy of our models since for dataset 1, we have to improve the accuracy of 5 distinct models, but for dataset 2 we only have to improve the accuracy of a single model.
Quantitative Approach
The first step to a more formulaic and quantitative approach is solving our g(f(x)) problem. We must remove g(x) and focus on codifying f(x) into an algorithm that is repeatable and measurable. The reasoning behind this is the work done by Robyn Dawes in his 1979 Paper The Robust Beauty of Improper Linear Models in Decision Making where he found that even sub-optimal linear models outperformed the analysis of experienced clinicians.
This is why I am in favor of a simple quantitative model that can express nuance and ranking of particular risks important to the health of the business.
For example, a score of 6.9 and 7.9 may have traditionally been rated as “High” and communicated as such. The “High” rating would have landed in the engineer’s work queue, but then the engineer would have to reach back out to the security team on which one to prioritize first since, on paper, they are equivalent. By assigning a score, we can create a simple stack-ranking system for the prioritization of vulnerabilities.
Creating Your Model
I highly recommend you create a model that works for your particular business because generic risk models will contain significant errors and you will underweight risks that are catastrophic for you, but not for others. This is why CVSS has failed to be widely adopted as the de-facto risk scoring solution for security issues.
Aa manufacturing plant may not care much about data protection, but the availability of the network and systems their equipment runs is paramount. A model that prioritizes access to data will fail to provide meaningful information to the business about their cybersecurity risks.
We must also be careful not to go overboard here because every additional variable comes with risk through its susceptibility to error. The more variables there are, the more effect the error has on our final calculation.
Finally, this is an iterative process that must be fine-tuned over time as you gather data and get feedback. Luckily, if you are using a simple formula then it will be easy to adjust.
Conclusion
I hope you have enjoyed my weekend rant on the state of cybersecurity. Next week, I’ll be getting into time probability vs ensemble probability and what the implications are for us as cybersecurity professionals. Until then, have a great weekend.